
衣服数据集-麻将胡了pg电子网站
订阅方案:
普通用户:¥30.00
vip用户:¥0.00
联系客服
查看订阅方案
数据集简介:
衣服数据集总共收集了 20 种衣服的 5,000 张图像。该数据集是根据公共领域许可 (cc0) 发布的。我们使用了三种不同的方式来收集数据集: toloka——众包平台;社交媒体上的网络众包计划; tagias——一家专门从事数据收集的公司。标签是使用 ipython 小部件手动完成的,同时我们使用简单的神经网络纠正了标签错误。 数据集包含 20 个类,包括t 恤(1011 件),长袖(69
推荐数据集
-

stanford 汽车图片数据
共享cars 数据集包含 196 类汽车的 16,185 张图像。 数据分为 8,144 个训练图像和 8,041 个测试图像,其中每个类别大致按 50-50 分割。 课程通常在品牌、型号、年份级别,例如 2012 tesla model s 或 2012 bmw m3 coupe。citationif you use this dataset, please cite the following p
-
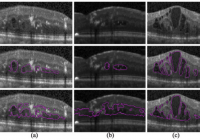
糖尿病性黄斑水肿的oct图像数据集
共享本数据集使用杜克企业数据统一内容浏览器搜索引擎追溯识别杜克眼科中心医学视网膜实践中的患者,并使用与他们就诊相关的 dme (icd-9 362.07) 计费代码。然后,一名眼科医生使用标准 spectralis(heidelberg engineering,heidelberg,germany)61 线体积扫描协议确定了 6 名临床成像的患者,这些患者具有严重的 dme 病理学和不同的图像质量。
-
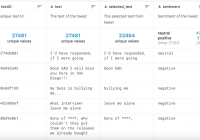
twitter 情绪推文数据集
共享数据集介绍: twitter 是一个在线社交媒体平台,人们在其中以推文的形式分享他们的想法。据观察,有些人滥用它来发布仇恨内容。twitter 正试图解决这个问题,我们将通过创建一个强大的基于 nlp 的分类器模型来帮助它来区分负面推文并阻止此类推文。你能建立一个强大的分类器模型来预测吗?每行包含一条推文的文本和一个情绪标签。在训练集中,您将获得一个从推文 (selected_text) 中提取的
-

综合汽车数据集
共享该数据集是被cvpr 2015 论文“用于细粒度分类和验证的大规模汽车数据集”所使用的。综合汽车 (compcars) 数据集包含来自两个场景的数据,包括来自网络自然和监视自然的图像。 web-nature 数据包含 163 个汽车制造商和 1,716 个汽车型号。 总共有 136,726 张拍摄整车的图像和 27,618 张拍摄汽车零件的图像。 完整的汽车图像标有边界框和视点。 每个车型都标有五

客服微信