
twitter 情绪推文数据集-麻将胡了pg电子网站
订阅方案:
普通用户:¥30.00
vip用户:¥0.00
联系客服
查看订阅方案
数据集简介:
数据集介绍: twitter 是一个在线社交媒体平台,人们在其中以推文的形式分享他们的想法。据观察,有些人滥用它来发布仇恨内容。twitter 正试图解决这个问题,我们将通过创建一个强大的基于 nlp 的分类器模型来帮助它来区分负面推文并阻止此类推文。你能建立一个强大的分类器模型来预测吗?每行包含一条推文的文本和一个情绪标签。在训练集中,您将获得一个从推文 (selected_text) 中提取的
推荐数据集
-

宾夕法尼亚动作数据集
共享数据集介绍:penn action dataset(宾夕法尼亚大学)包含 15 个不同动作的 2326 个视频序列以及每个序列的人类联合注释。referenceif you use our dataset, please cite the following paper:weiyu zhang, menglong zhu and konstantinos derpanis, "from actem
-
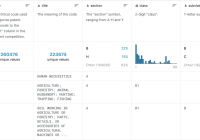
专利短语数据集
共享该数据集是为美国专利短语到短语匹配竞赛提供的。它通过提供context列中每个代码的含义来添加附加信息。
-

lisa交通灯数据集
共享为了为未来交通灯识别 (tlr) 研究的比较提供共同基础,我们根据美国道路的镜头收集了一个广泛的公共数据库。该数据库收集于美国加利福尼亚州圣地亚哥。该数据库提供了四个主要用于测试的白天和两个夜间序列,提供了在太平洋海滩和圣地亚哥拉霍亚的 23 分 25 秒的驾驶时间。该数据库由连续测试和训练视频序列组成,共有 43,007 帧和 113,888 个带注释的交通信号灯。这些序列由安装在车辆车顶上的立
-

nh-haze
共享数据集介绍: 这是一个非均匀的真实数据集,具有成对的真实雾度和相应的无雾度图像。这是第一个非齐次图像去模糊数据集,包含55个室外场景。在场景中引入了非均匀雾,使用专业雾发生器模拟雾场景的真实条件。 引用: @inproceedings{nh-haze_2020, author = {codruta o. ancuti and cosmin ancuti and radu timofte}, t

客服微信