- 热门标签
综合数据 共找到数据集 120 个
全部
- 全部
- 共享
- 商用
全部
- 全部
- 月萌api
- 第三方
-

cctv新闻联播文字版包含cctv中央电视台2007年-2022年最新的每日播放内容文字版,内容丰富多样,包含国际国内经济、政治、文化、体育等等多个方面的信息,被称为“中国政坛的风向标”, 具有极高的研究挖掘价值。
供应商:moonapi2007-2022年16年超全新闻联播文字版优质文本数据源内容丰富高研究挖掘价值 -

look into person(lip)是一个新的大规模数据集,专注于人的语义理解,该数据集包含 50,000 张图像,其中包含精心设计的像素注释、19 个语义人体部位标签和具有 16 个关键点的 2d 人体姿势。带注释的 50,000 张图像是从 coco 数据集中裁剪的人物实例,大小大于 50 * 50。从真实场景收集的图像包含以具有挑战性的姿势和视图出现的人类、严重遮挡、各种外观和低分辨率。
供应商:moonapi大规模数据集50,000 张图像,精心设计的像素注释19 个语义人体部位标签和具有 16 个关键点的 2d 人体姿势 -

descriptionai-tod 在 28,036 张航拍图像中包含 8 个类别的 700,621 个对象实例。 与现有航拍图像中的目标检测数据集相比,ai-tod 中目标的平均大小约为 12.8 像素,远小于其他数据集。citationif you use this dataset in your research, please cite these papers.@inproceeding
供应商:moonapi优质数据集论文常用数据集数据集大小 23498.06 mb -
这个数据集由440个声音组成,包含猫在不同环境中发出的喵喵声。具体来说,属于2个品种(缅因猫和欧洲短毛猫)的21只猫反复暴露于三种不同的刺激
供应商:moonapi数据集由440个声音组成2个品种(缅因猫和欧洲短毛猫)的21只猫 -

description在 tinyperson 中有 1610 个标记图像和 759 个未标记图像(两者主要来自同一视频集),总共有 72651 个注释。tiny person detection taskfor tiny person detection task, the rules of evaluation on test set are given as follows:we treat
供应商:moonapi优质数据集论文常用数据集数据集大小 1679.72 mb -

数据集介绍: 这24个数据集是由潘广汉、孙天生、托比·威德和丹尼尔·沙尔斯坦在2019-2021期间创建的。数据集包括11个场景,在许多不同的照明条件和曝光(包括移动设备的闪光灯和“手电筒”照明)下,从1-3个不同的观看方向成像。 references: [1] d. scharstein and r. szeliski. a taxonomy and evaluation of
供应商:moonapi优质数据集论文常用数据集数据集大小 403.72 mb -
 mnist数据集是一个手写阿拉伯数字图像识别数据集,图片分辨率为 20x20 灰度图图片,包含‘0 - 9’ 十组手写手写阿拉伯数字的图片。其中,训练样本 60000 ,测试样本 10000,数据为图片的像素点值,作者已经对数据集进行了压缩。overviewthe mnist database of handwritten digits, has a training set of 60,000供应商:moonapi优质数据集论文常用数据集数据集大小 10.16 mb
mnist数据集是一个手写阿拉伯数字图像识别数据集,图片分辨率为 20x20 灰度图图片,包含‘0 - 9’ 十组手写手写阿拉伯数字的图片。其中,训练样本 60000 ,测试样本 10000,数据为图片的像素点值,作者已经对数据集进行了压缩。overviewthe mnist database of handwritten digits, has a training set of 60,000供应商:moonapi优质数据集论文常用数据集数据集大小 10.16 mb -

数据集介绍aist 舞蹈动作数据集是从 aist 舞蹈视频数据库构建的。 对于多视图视频,设计了一个精心设计的管道来估计相机参数、3d 人体关键点和 3d 人体舞蹈动作序列:它为 1010 万张图像提供 3d 人体关键点注释和相机参数,涵盖 9 个视图中的 30 个不同主题。 这些属性使其成为具有 3d 人体关键点注释的最大和最丰富的现有数据集。它还包含 1,408 个 3d 人类舞蹈动作序列
供应商:moonapi优质数据集论文常用数据集数据集大小 2395.1 mb -
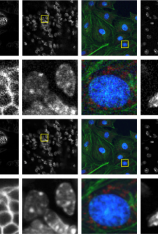
荧光显微镜使现代生物学取得了巨大的发展。由于其固有的微弱信号,荧光显微镜不仅比摄影噪声大得多,而且还呈现出泊松-高斯噪声,其中泊松噪声或散粒噪声是主要的噪声源。为了获得干净的荧光显微镜图像,非常需要有专门设计用于对荧光显微镜图像进行降噪的有效降噪算法和数据集。虽然存在这样的算法,但没有这样的数据集可用。在本文中,我们通过构建专用于泊松-高斯去噪的数据集 - 荧光显微镜去噪 (fmd) 数据集来填补
供应商:moonapi优质数据集论文常用数据集数据集大小 8525.67 mb


客服微信