零售产品结账数据集-麻将胡了pg电子网站
订阅方案:
普通用户:¥30.00
vip用户:¥0.00
联系客服
查看订阅方案
数据集简介:
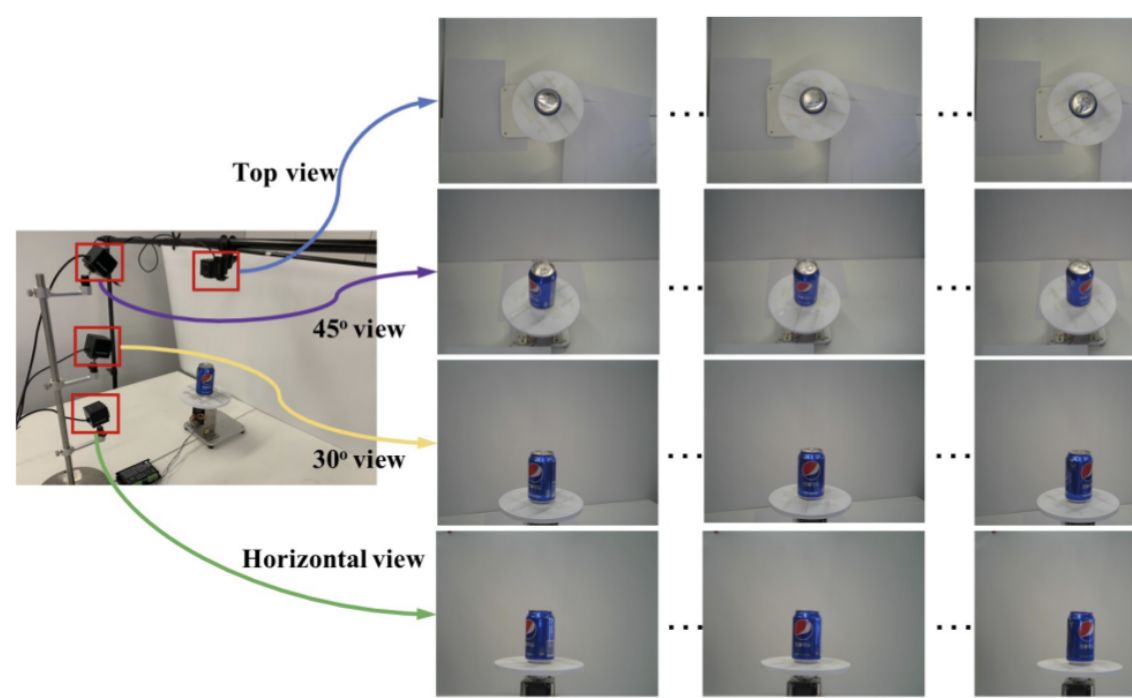
数据集介绍 近年来,人们对将计算机视觉技术集成到零售行业产生了新的兴趣。自动结账 (aco) 是该领域的关键问题之一,旨在从要购买的产品图像中自动生成购物清单。这个问题的主要挑战来自产品类别的大规模和细粒度特性,以及由于产品的不断更新,难以收集反映真实结账场景的训练图像。尽管具有重要的实践和研究价值,但这个问题在计算机视觉社区中并没有得到广泛的研究,主要是由于缺乏高质量的数据集。为了填补这一空白,
推荐数据集
-

cbcl 街道场景数据
共享streetscenes challenge framework 是用于对象检测的图像、注释、软件和性能测量的集合。 每张图像都是从马萨诸塞州波士顿及其周边地区的 dsc-f717 相机拍摄的。 然后用围绕 9 个对象类别的每个示例的多边形手动标记每个图像,包括 [汽车、行人、自行车、建筑物、树木、天空、道路、人行道和商店]。 这些图像的标记是在仔细检查下完成的,以确保对象总是以相同的方式标记,关
-

argoverse数据集
共享argoverse针对的任务:3d追踪和动作预测,两个任务对应的数据集其实是独立的,只是采集设备和采集地点一样而已。提供了360度的视频和点云信息,并根据点云重建了地图,全天候全光照。标注了视频和点云中的3d bounding box。3d追踪的数据集包含113段15-30秒的视频,动作预测中包含323,557段5秒的视频(总计320小时)。数据集的主要亮点还是在原始数据和地图的联动上。
-

lidar 2d深度图像数据集
共享该数据集包含 2d 深度图像,如下图所示。像 kitti 数据集中的 360 度 lidar 框架在传感器本身周围呈圆柱形。该数据集中的 2d 深度图像可以表示为您在 lidar 框架的圆柱体上进行了切割并将其拉直以位于 2d 平面中。这些 2d 深度图像的像素代表反射物体与 lidar 传感器的距离。 2d 深度图像的垂直分辨率(在我们的例子中为 64)表示用于扫描周围环境的 lidar 传感器
-
lytro illum
共享数据集介绍: 收集了 640 个在大小、纹理、背景杂波和照明等方面具有显着变化的光场。生成微透镜图像阵列和中心观察图像,并生成相应的地面实况图。 citation if you find our paper and repo useful, please cite our paper. thanks! @article{zhang2020, title={light field sa

客服微信