
cbcl 街道场景数据-麻将胡了pg电子网站
订阅方案:
普通用户:¥30.00
vip用户:¥0.00
联系客服
查看订阅方案
数据集简介:
streetscenes challenge framework 是用于对象检测的图像、注释、软件和性能测量的集合。 每张图像都是从马萨诸塞州波士顿及其周边地区的 dsc-f717 相机拍摄的。 然后用围绕 9 个对象类别的每个示例的多边形手动标记每个图像,包括 [汽车、行人、自行车、建筑物、树木、天空、道路、人行道和商店]。 这些图像的标记是在仔细检查下完成的,以确保对象总是以相同的方式标记,关
推荐数据集
-
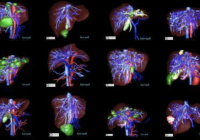
3d-ircadb脏器分割数据集
共享3d-ircadb-01 数据库由 10 名女性和 10 名男性 75% 的肝肿瘤患者的 3d ct 扫描组成。 20个文件夹对应20个不同的患者,可以单独下载也可以联合下载。下表提供了图像信息,例如肝脏大小(宽度、深度、高度)或根据 couninaud 分割的肿瘤位置。它还表明肝脏分割软件可能遇到的主要困难是由于与邻近器官的接触、肝脏的非典型形状或密度,甚至图像中的伪影。 for refer
-

camseq 2007数据集
共享camseq是一个地面数据集,可自由用于视频目标识别中的研究工作。该数据集包含 101 个 960x720 像素的图像对。 每个掩码都由文件名之外的“_l”指定。 所有图像(原始图像和真实图像)均为未压缩的 24 位彩色 png 格式。 该数据集最初是针对自动驾驶汽车的问题而设计的。此序列描绘了从一辆动感的汽车拍摄的剑桥市的动感驾驶场景。这是一个具有挑战性的数据集,因为除了汽车的自我运动之外,其他
-
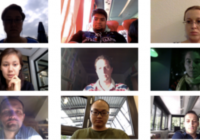
mpiigaze数据集
共享数据集介绍: 基于外观的凝视估计被认为在现实环境中很有效,但现有数据集是在受控实验室条件下收集的,并且没有对多个数据集的方法进行评估。在这项工作中,我们研究了野外基于外表的凝视估计。我们展示了mpiigaze数据集,其中包含我们在三个多月的日常笔记本电脑使用过程中从15名参与者收集的213659张图像。在外观和照明方面,我们的数据集比现有的数据集变化更大。我们还提出了一种使用多模式卷积神经网络进行
-

sidd-small数据集
共享一个小型版本的数据集,它由代表 160 个场景实例的160 个图像对(噪声和ground-truth)组成。 papers abdelrahman abdelhamed, lin s., brown m. s. "a high-quality denoising dataset for smartphone cameras", ieee computer vision and pattern

客服微信