
小目标检测数据集-麻将胡了pg电子网站
订阅方案:
普通用户:¥30.00
vip用户:¥0.00
联系客服
查看订阅方案
数据集简介:
从internet(例如youtube或google)上的图像/视频收集的四个小物体数据集,包括4种类型的图像,可用于小物体目标检测的研究。数据集包含四类:fly:飞行数据集,包含600个视频帧,平均每帧86±39个物体(648×72 @ 30 fps)。 32张图像用于训练(1:6:187),50张图像用于测试(301:6:600)。honeybee:蜜蜂数据集,包含118张图像,每张图像平均有
推荐数据集
-

密集行人检测数据集
共享describtionwiderperson 数据集是野外行人检测基准数据集,其图像选自广泛的场景,不再局限于交通场景。 我们选择了 13,382 张图像并标记了大约 400k 带有各种遮挡的注释。 我们随机选择 8000/1000/4382 图像作为训练、验证和测试子集。 与 citypersons 和 wider face 数据集类似,我们不发布测试图像的边界框基本事实。 用户需要提交最终的预
-

人群姿态数据集
共享数据集介绍: 多人姿态估计是许多计算机视觉任务的基础,近年来取得了重大进展。然而,以前很少有方法研究拥挤场景中的姿态估计问题,而在许多场景中,这仍然是一个具有挑战性和不可避免的问题。此外,目前的基准无法对此类案件进行适当评估。在本文中,我们提出了一种新的有效方法来解决人群中的姿势估计问题,并提出了一个新的数据集来更好地评估算法。 citation if you find our works u
-

sidd智能手机图像去噪数据集
共享由于小光圈和传感器尺寸,智能手机图像通常比数码单反相机具有更多的噪点。考虑到图像去噪是一个活跃的研究领域,作者提出了一个去噪图像数据集,该数据集代表来自智能手机相机的真实噪声图像,具有高质量的地面实况。该数据集与cvpr 2020一起用于ntire 2020 真实图像去噪挑战赛。 该数据集包含以下智能手机在不同光照条件下拍摄的 160 对噪声/真实图像: gp: google pixelip:
-
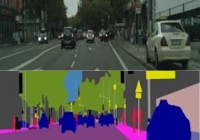
城市景观图像对数据集
共享城市景观数据(数据集pg电子试玩链接主页)包含从德国驾驶的车辆中拍摄的标记视频。此版本是作为 pix2pix 论文的一部分创建的已处理子样本。数据集包含来自原始视频的静止图像,语义分割标签与原始图像一起显示在图像中。这是语义分割任务的最佳数据集之一。 该数据集有 2975 个训练图像文件和 500 个验证图像文件。 每个图像文件为 256x512 像素,每个文件是与图像左半部分的原始照片以及右半部分的标记图像

客服微信