
推荐数据集
-
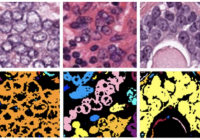
kumar肿瘤数据集
共享这一数据集是通过仔细注释几名患有不同器官肿瘤并在多家医院被诊断出的患者的组织图像获得的。该数据集是通过从tcga存档下载以 40 倍放大倍率捕获的 h&e 染色组织图像创建的。h&e 染色是增强组织切片对比度的常规方案,通常用于肿瘤评估(分级、分期等)。考虑到多个器官和患者的细胞核外观的多样性,以及多家医院采用的丰富染色方案,训练数据集将能够开发出开箱即用的稳健且可推广的细胞核分割技术。 ci
-

交通摄像头检测数据集
共享该数据集是来自伊利诺伊州芝加哥市交通摄像头的增强随机屏幕截图的集合。在数据中,所有车辆都被标记在一个名为 的类别中car。标签由边界框组成,并以 yolov5 pytorch 格式存储。 acknowledgements snyder, corey; do, minh (2019): data for streets: a novel camera network dataset for tr
-

90种动物图像数据集
共享在这个数据集中有 90 个不同类别的 5400 张动物图像。此数据集是从 google 图片创建的:https://images.google.com/。所有照片将按照其所属类别存放于各自的文件夹下。动物类别包括:羚羊,獾,蝙蝠,熊,蜜蜂,甲虫,野牛,公猪,蝴蝶,猫毛虫,黑猩猩等。该数据集中的图像大小不固定,可能需要后续的处理。
-

食物图像数据集
共享该数据集包含完整 food-101 数据的许多不同子集。为了给图像分析制作一个比 cifar10 或 mnist 更简单的训练集,该数据包括图像的大规模缩小版本,以实现快速测试。数据已被重新格式化为 hdf5,特别是 keras hdf5matrix,这样可以轻松读取它们。文件名表示文件的内容。例如 foodc101n1000_r384x384x3.h5 表示有 101 个类别,n=1000

客服微信