
driveseg场景分割数据集-麻将胡了pg电子网站
订阅方案:
普通用户:¥30.00
vip用户:¥0.00
联系客服
查看订阅方案
数据集简介:
我们提供了 mit driveseg 数据集,这是一个大规模的驾驶场景分割数据集,为 5,000 个视频帧中的每个像素和每个像素都进行了密集注释。这个数据集是一个面向前的逐帧像素级语义标记数据集,该数据集是在连续白天驾驶通过拥挤的城市街道时从移动的车辆捕获的。该数据集的目的是允许探索时间动态信息的价值,以便在动态的真实操作环境中进行全场景分割。
推荐数据集
-

猫咪数据集
共享contextthe cat dataset includes over 9,000 cat images. for each image, there are annotations of the head of cat with nine points, two for eyes, one for mouth, and six for ears.contentthe annotation da
-

宜家asm数据集
共享数据集介绍:宜家 asm 数据集是装配任务的多模式和多视图视频数据集,可对人类活动进行丰富的分析和理解。 它包含 371 个家具组件样本及其真实注释。 每个样本包括 3 个 rgb 视图、一个深度流、原子动作、人体姿势、对象片段、对象跟踪和外部相机校准。 此外,我们在指定的 github 存储库中提供用于数据处理的代码,包括深度到点云的转换、表面法线估计、可视化和评估。if you use the
-
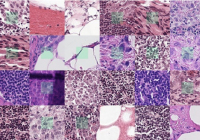
淋巴结切片的组织病理学数据集
共享patchcamelyon 是一个新的且具有挑战性的图像分类数据集。它由从淋巴结切片的组织病理学扫描中提取的 327.680 张彩色图像 (96 x 96px) 组成。每个图像都带有一个二进制标签,表示存在转移组织。pcam 为机器学习模型提供了新的基准:大于 cifar10,小于 imagenet,可在单个 gpu 上训练。 usage and tips keras example gene
-
olist电子商务公共数据集
共享这是在olist store下订单的巴西电子商务公共数据集。该数据集包含 2016 年至 2018 年在巴西多个市场进行的 10 万份订单的信息。它的功能允许从多个维度查看订单:从订单状态、价格、付款和货运绩效到客户位置、产品属性,最后是客户撰写的评论。这是真实的商业数据,已匿名,评论文本中对公司和pg电子试玩链接的合作伙伴的引用已替换为《权力的游戏》大家族的名称。

客服微信